Muchos problemas de optimización tienen una alta complejidad, debido a que generalmente son problemas de NP-duras y también porque el tiempo que se posee para resolverlos es muy limitado; por tanto la informática se ha convertido en pieza clave para la resolución de estos, usando métodos exactos y heurísticos, los cuales son capaces de encontrar muy buenas soluciones en un tiempo y consumo de recursos razonables.
Entre las técnicas heurísticas, se encuentran los algoritmos basados en cúmulos de partículas, concretamente el método denominado Particle Swarm Optimization (PSO).
Esta técnica fue desarrollada por el psicólogo-sociólogo Jammes Kennedy y por el ingeniero electrónico Russell Eberhart en 1995, fundamentándose en experimentos con algoritmos que modelaban el comportamiento en vuelo observado en algunas especies de pájaros, o el comportamiento de los bancos de peces, incluso las tendencias sociales en el comportamiento humano.
En este algoritmo, cada individuo, llamado partícula, se va moviendo en un espacio multidimensional que representa su espacio social. Cada partícula tiene memoria mediante la que conserva parte de su estado anterior. Cada movimiento de una partícula es la composición de una velocidad inicial aleatoria y dos valores ponderados aleatoriamente: individual (la tendencia de las partículas de preservar su mejor estado anterior) y social (la tendencia a moverse hacia vecinos con mejor posición).
Debido a su planteamiento, este tipo de algoritmo se adapta muy bien a problemas de programación lineal y entera.
Este problema se plantea de la siguiente manera: se supone que una bandada de aves busca comida en un área y que solamente hay una pieza de comida en dicha área. Los pájaros no saben dónde está la comida pero sí conocen su distancia a la misma, por lo que la estrategia más eficaz para hallar la comida es seguir al ave que se encuentre más cerca de ella. PSO utiliza este escenario para resolver problemas de optimización.
Cada solución (partícula) es un ave en el espacio de búsqueda que está siempre en continuo movimiento y que nunca muere.
El modelo del PSO, es:
 : velocidad de la partícula i en la iteración k.
: velocidad de la partícula i en la iteración k.
ⱳ: factor inercia.
 : son ratios de aprendizaje (pesos) que controlan los componentes cognitivo y social.
: son ratios de aprendizaje (pesos) que controlan los componentes cognitivo y social.
rand1; rand2 : números aleatorios entre 0 y 1.
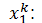 : posición actual de la partícula i en la iteración k.
: posición actual de la partícula i en la iteración k.
pBesti : mejor posición (solución) encontrada por la partícula i hasta el momento.
gi : representa la posición de la partícula con el mejor pBest_fitness del entorno de pi (lBest o localbest) o de todo el cúmulo (gBest o globalbest).
El modelo se representa en las siguientes ecuaciones:
La primera ecuación, refleja la actualización del vector velocidad de cada partícula i en cada iteración k.
Tipos de Algoritmos de PSO.
Existe muchos tipos de PSO que atienden diversos factores, como lo son: según la importancia de los pesos cognitivo, social y según el tipo de vecindario utilizado.
Ya dependiendo de la influencia de los factores cognitivo y social sobre la dirección de la velocidad que toma una partícula en el movimiento identifica cuatro tipos de algoritmos:
- Modelo Completo: Tanto el componente cognitivo como el social intervienen en el movimiento.
- Modelo sólo Cognitivo: Únicamente el componente cognitivo interviene en el movimiento.
- Modelo sólo Social: Únicamente el componente social interviene en el movimiento.
- Modelo sólo Social exclusivo: La posición de la partícula en sí no puede ser la mejor de su entorno.
·
Por otra parte desde el punto de vista del vecindario es decir, la cantidad y posición de las partículas que intervienen en el cálculo de la distancia en la componente social, se clasifican dos tipos de algoritmos: PSO Local y PSO Global.
En el PSO Local, se calcula la distancia entre la posición actual de partícula y la posición de la mejor partícula encontrada en el entorno local de la primera. El entorno local consiste en las partículas inmediatamente cercanas en la topología del cúmulo.
Para el PSO Global, la distancia en el componente social viene dada por la diferencia entre la posición de la partícula actual y la posición de la mejor partícula encontrada en el cúmulo completo. La versión Global converge más rápido pues la visibilidad de cada partícula es mejor y se acercan más a la mejor del cúmulo favoreciendo la intensificación, por esta razón, también cae más fácilmente en óptimos locales.
Topologías del Cúmulo de Partículas.
Hay que resaltar algo muy importante, y es la manera en que una partícula interacciona con las demás partículas de su vecindario. El desarrollo de una partícula depende tanto de la topología del cúmulo como de la versión del algoritmo. Las topologías definen el entorno de interacción de una partícula individual con su vecindario. La propia partícula siempre pertenece a su entorno. Los entornos pueden ser de dos tipos:
- Geográficos: se calcula la distancia de la partícula actual al resto y se toman las más cercanas para componer su entorno.
- Sociales: se define a priori una lista de vecinas para partícula, independientemente de su posición en el espacio.
Un problema habitual de los algoritmos de PSO es que la magnitud de la velocidad suele llegar a ser muy grande durante la ejecución, con lo que las partículas se mueven demasiado rápido por el espacio. El rendimiento puede disminuir si no se fija adecuadamente el valor de vmax, la velocidad máxima de cada componente del vector velocidad.
Por último podemos decir que este algoritmo se aplica en diferentes campos de investigación. Entre ellos están: la optimización de funciones numéricas, el entrenamiento de redes neuronales, el aprendizaje de sistemas difusos, el registrado de imágenes, el problema del viajante de comercio e ingeniería química.
REFERENCIAS:
- Algoritmos Basados en Cúmulos de Partículas Para la Resolución de Problemas Complejos
- Autor: José Manuel García Nieto
- Directores: Enrique Alba Torres y Gabriel Jesús Luque Polo
- septiembre de 2006






















